和体渲染爆了:一文看懂Exponential Media Transmittance Estimation
前言:笔者在一次大组会上讲了一下体渲染的基础知识和几个话题,然后老板说讲的太快,没怎么听懂Transmittance Estimation,建议我小组会上详细讲讲。不幸的是,笔者准备大组会只是skim了一下话题相关的paper,然后主要贴了一些结论,并没有深入地看。老板发令,于是又把相关论文详细读了一遍,研究了一下相关的知识,手推了很多公式。笔者读了几篇非常长的论文深感痛苦(从文章标题可见一斑),看到太多二级结论,只得阅读了很多数学上的资料,所以写下这篇文章,期望能够帮助各位理解。
如果你喜欢这篇文章,可以在知乎上点赞/喜欢/收藏!
主要参考文献
为方便读者翻阅,先把参考文献列出;笔者阅读的主要论文包括:
- Residual ratio tracking for estimating attenuation in participating media, ToG 2014
- Monte Carlo Methods for Volumetric Light Transport Simulation, CGF 2018
- Integral formulations of volumetric transmittance, ToG 2019
- Direct Transmittance Estimation in Heterogeneous Participating Media Using Approximated Taylor Expansions, TVCG 2020
- An unbiased ray-marching transmittance estimator, ToG 2021
疑似NVIDIA这篇ToG 2021之后就没有直接的后续工作了;阅读的其他一些论文不是渲染领域的,列到参考文献里。经师兄提醒,本文的体渲染描述的是经典的参与介质假设,在ToG 2018有paper开始讨论不满足指数衰减的介质,因此为了严谨,标题加上了“Exponential Media”的限制。
Notations
由于体渲染不同材料中的符号不同,本文的$\mu$和$\sigma$会混用,但同一个公式的符号是统一的。具体地:
- $\bar\mu$和$\sigma_{maj}$一致,表示extinction的一个上界(majorant);
- $\mu$和$\sigma_t$一致,表示extinction;
- $\mu_n$和$\sigma_n$一致,表示$\sigma_{maj}-\sigma_t$。
Motivation
先简单复习一下体渲染的流程,然后介绍为什么需要Transmittance Estimation,熟悉者可跳过。
Volumetric Rendering Equation
我们知道体渲染方程($w$的正负号看记号规定,这里直接用PBRT的):
\[L_i(p,w)=T_r(p_s\rightarrow p)L_o(p_s,-w)+\int_0^{t_s} T_r(p'\rightarrow p)\sigma_t(p',w)L_s(p',-w)\mathrm dt\]即incident radiance要考虑:
- $T_r(p_s\rightarrow p)L_o(p_s,-w)$,表示打到非参与介质(如表面)的位置$p_s$的radiance再乘以穿越介质导致的衰减;
- $\int_0^{t_s} T_r(p’\rightarrow p)\sigma_t(p’,w)L_s(p’,-w)\mathrm dt$,表示要考虑当前光路各个位置的radiance。
其中:
- \[L_s(p,w)=\frac{\sigma_a(p,w) L_e(p,w)+\sigma_s(p,w)\int_{S^2}\phi(p,w_i,w)L_i(p,w_i)\mathrm dw_i}{\sigma_t(p,w)}\]
表示每个位置的自发光,加上从各个方向散射来的radiance(通过phase function $\phi$加权,即类似于表面的BSDF项);除以$\sigma_t=\sigma_a+\sigma_s$可以和radiance保持量纲一致。
- \[T_r(p\rightarrow p')=e^{-\int_0^d\sigma_t(p+tw,w)\mathrm dt},\text{where }\ d=\|p-p'\|_2\]
这一项被称为Transmittance,描述了光沿介质传播的能量衰减;我们常称$\int_0^d\sigma_t(p+tw,w)\mathrm dt$为光学厚度/深度(optical thickness / depth),不妨记作$\tau$。
以上是通过体渲染的微分积分方程通过常微分方程推导出来的理论公式。为了估计$L_i$,在离线渲染和实时渲染中有着不同的方法。
We Need to Estimate Transmittance!
在离线渲染中,为了保证无偏性,我们通常进行蒙特卡洛估计(后简称MC)。一种经典的方式就是先通过Russian Roulette(RR):
\[\hat L= \begin{cases} \frac{1}{q}T_r(p_s\rightarrow p)L_o(p_s,-w) & u\in[0,q)\\ \frac{1}{1-q}\int_0^{t_s} T_r(p'\rightarrow p)\sigma_t(p',w)L_s(p',-w)\mathrm dt & u\in[q,1] \end{cases}\]其中$u\in U[0,1],q\in(0,1)$;以$q$的概率选择第一项,以$1-q$的概率选择第二项,则$E[\hat L]$和原式相等。注意到第二个式子仍然是积分式,所以需要再次MC:
\[\hat L=\frac{T_r(x\rightarrow p)\sigma_t(x,w)L_s(x,-w)}{p(x)}\]因此总是要估计Transmittance;事实上由于$L_s$还包括积分,需要进一步MC。
在实时渲染中,为了渲染速度,通常使用Ray marching的有偏方式,即使用黎曼和来估计:
\[\int_0^{t_s} T_r(p'\rightarrow p)\sigma_t(p',w)L_s(p',-w)\mathrm dt\approx \sum_{i=1}^NT_r(p'_i\rightarrow p)\sigma_t(p'_i,w)L_s(p'_i,-w)\delta t_i\]同样需要估计Transmittance。
注:
- 离线渲染的过程中,有一些方式可以巧妙地绕过Transmittance的计算,但是固定了采样的方式,我们在Appendix中会给出。
- 实时渲染也可以用离线渲染的方法,例如UE中提供的sky rendering中有PathTracing.hlsl和RayMarching.hlsl两种。
Back to Basics: Poisson Point Process
在介绍如何估计transmittance之前,先复习一点概率统计的知识。
Poisson Distribution
在离散型随机变量中,有三种非常常见的分布:
- 伯努利分布(Bernoulli Distribution):进行一次试验,只有0和1两种结果,成功概率由唯一参数$p$决定;即其概率分布PMF为$P(X=1)=p, P(X=0)=1-p$;$E(X)=p$。
- 抛一次硬币,正反概率相同,此时$p=0.5$。
- 二项分布(Binomial Distribution):进行$n$次试验,每次试验满足伯努利分布且互相独立,则关于发生次数$k$的PMF为:$P(X=k)=C_n^k p^k (1-p)^k$;$E(X)=np$。
- 抛n次硬币,得到k次正面的概率。
- 泊松分布(Poisson Distribution):二项分布只能描述离散试验;然而有些情况下,单位时间内每时每刻都可能发生事件,但成功概率极小,只能满足$\lim_{n\rightarrow \infty}np=\lambda$。在这无穷次试验中,成功$k$次的概率为$P(X=k)=λ^ke^{-λ}/k!$;$E(X)=\lambda$。
- 比如90分钟的球赛,每时每刻都有可能进球,但是我们只知道最终平均进球数量为2.5,则可以用$λ=2.5$的泊松分布来计算实际进球数量的概率。
泊松分布本质上在描述这样的过程:
- 每时每刻的事件相互独立,成功概率均匀,前一时刻的事件不会影响后一时刻的事件发生的概率;
- 同时在给定时间内,平均会发生$λ$次成功事件。
Properties of Poisson Distribution
泊松分布有几条非常神奇的性质:
-
两次成功事件之间的时间间隔为连续随机变量,满足指数分布$Exp(\lambda)$。
证明:由于成功概率均一,不妨假设$T$时刻发生下一次事件;我们可以反过来求$T$时刻还没发生事件的概率$P(X=0)=e^{-λT}$(这是因为假设单位时间内平均发生λ次,若以T为单位时间,则平均为$λT$次)。
因此,CDF $P(t≤T)=1-e^{-λT}$,故求导得到PDF $p(t)=λe^{-λt}$。
-
如果事件发生的时间间隔满足指数分布,则事件发生次数满足泊松分布。
证明:$P(X=0)$同上易证,则可以使用数学归纳法;假设$P(X=k)$满足泊松分布,则:
\[\begin{aligned} P(X=k+1) & =\int_0^t P\left(\text {First arrival at } t_1<t \text { and exactly } k \text { arrivals between } t_1 \text { and } t\right) \mathrm d t_1 \\ & =\int_0^t \lambda \exp \left(-\lambda t_1\right)\left(\lambda\left(t-t_1\right)\right)^k \frac{\exp \left(-\lambda\left(t-t_1\right)\right)}{k!} d t_1 \\ & =\frac{\lambda^{k+1} \exp (-\lambda t)}{k!} \int_0^t\left(t-t_1\right)^k d t_1 \\ & =\frac{(\lambda t)^{k+1} \exp (-\lambda t)}{(k+1)!} \end{aligned}\] -
若已知在当前时间段内发生了一次事件,则事件发生的时间是均匀分布的。形式化地,即$P(x)=P(X≤x∣N_t=1)=x/t$ $\Rightarrow p(x)=1/t$。
证明:
\[\begin{aligned} P\left(S_1 \leq\right. \left.x \mid N_t=1\right)&=\frac{P\left(S_1 \leq x, N_t=1\right)}{P\left(N_t=1\right)} \\ & =\frac{P\left(N_x=1, N_t-N_x=0\right)}{P\left(N_t=1\right)} \\ & = \frac{P\left(N_x=1\right) P\left(N_t-N_x=0\right)}{P\left(N_t=1\right)} \\ & =\frac{P\left(N_x=1\right) P\left(N_{t-x}=0\right)}{P\left(N_t=1\right)} \\ & =\frac{\alpha x e^{-\alpha x} \cdot e^{-\alpha(t-x)}}{\alpha t e^{-\alpha t}}=\frac{x}{t} \end{aligned}\]推广结论:若在当前段内发生了$N$次事件,则$N$次事件服从$\text{i.i.d.} U[0, t]$。证明可见StackExchange。
Non-Stationary Poisson Distribution
我们之前考虑的泊松分布是一种比较特殊的情况,即成功概率均匀;但如果成功概率不均匀呢?我们不妨先考虑一种最简单的情况:分两段的均匀泊松分布。
设在第一个时间段内满足$N∼\text{Po}(λ_1)$,第二段满足$N∼\text{Po}(λ_2)$,则在整个时间段内发生$n$次成功事件的概率是在两段上成立$k$和$n-k$次再作和:
\[P(N=n)=\sum_{k=0}^n \frac{\lambda_1^k}{k!} e^{-\lambda_1} \cdot \frac{\lambda_2^{n-k}}{(n-k)!} e^{-\lambda_2}=e^{-\left(\lambda_1+\lambda_2\right)} \sum_{k=0}^n \frac{\lambda_1^k}{k!} \cdot \frac{\lambda_2^{n-k}}{(n-k)!}\]根据二项式定理:
\[\sum_{k=0}^nC_n^k \lambda_1^k \lambda_2^{n-k}=\left(\lambda_1+\lambda_2\right)^n \Rightarrow \sum_{k=0}^n \frac{\lambda_1^k}{k!} \cdot \frac{\lambda_2^{n-k}}{(n-k)!}=\frac{\left(\lambda_1+\lambda_2\right)^n}{n!}\\\]于是:
\[P(N=n)=\frac{\left(\lambda_1+\lambda_2\right)^n}{n!} e^{-\left(\lambda_1+\lambda_2\right)}\]因此,整体来看,$N\sim \text{Po}(\lambda_1+\lambda_2)$;但由于中间概率会发生变化,性质会稍微差一点,例如整体的到达时间不会满足指数分布。
Poisson Point Process (PPP)
更一般地,事件的发生概率是时刻变化的,也即只能满足以下两条性质:
- 每时每刻的事件相互独立,前一时刻的事件不会影响后一时刻的事件发生的概率;
- 在时刻$t$,如果按照当前时刻的概率完成泊松分布,单位时间内平均会发生$λ(t)$次成功事件。
此时我们将这个过程称为泊松点过程(Poisson Point Process, PPP);泊松分布是均匀的泊松点过程(homogeneous PPP)。我们称$λ(t)$为intensity function或者rate function。
从微积分的角度看,我们可以认为在每个小$\delta$内$\lambda$不变,于是构成若干个分段泊松分布,可以推论:对任意$t_0\sim t_1$时段,事件发生次数满足$N\sim \text{Po}(\int_{t_0}^{t_1}\lambda(t)\mathrm dt)$,次数的期望$E(N)=\int_{t_0}^{t_1}\lambda(t)\mathrm dt$。特别地,$P(N=0)=e^{-\int_{t_0}^{t_1}\lambda(t)\mathrm dt}$。
在数学上PPP的定义更松弛,只通过极限来控制,笔者不能理解怎么从松弛的定义证明PPP的上述性质,只通过放缩+夹逼证明了$P(N=0)$;考虑到这个问题不影响我们讨论的主题,所以感兴趣的读者请见Appendix。
那么如何能够根据$\lambda(t)$采样出符合PPP的点序列呢?当然可以通过inverse CMF来完成,但是要计算积分,太复杂,所以最常用的方式称为Thinning(见其他参考文献[Pausupathy2011]):

简单来说就是应用了拒绝采样的原理,我们首先把PPP的$\lambda(t)$补足到一个上界$\lambda_u$,构成一个纯粹的泊松分布。对于这个泊松分布,我们可以使用指数分布来采出一个点序列。然而,由于我们实际上高估了事件的发生概率,因此还要拒绝掉一部分;拒绝的方式就是在当前点用一个$\lambda(t)/\lambda_u$的伯努利分布随机拒绝。严格的证明请见其他参考文献[Lewis & Shedler1978]。
Current Estimators
我们现在关注的核心为$T_r(p\rightarrow p’)=e^{-\int_0^d\sigma_t(p+tw,w)\mathrm dt}$;注意到还有一个积分,那么同样可以黎曼和有偏/MC无偏地估计。
Ray Marching Estimator
类似体渲染方程的估计,可以接着Ray marching:
\[e^{-\int_0^d\sigma_t(p+tw,w)\mathrm dt}\approx e^{-\sum_{i=1}^N \sigma_t(p_i',w)\mathrm \delta t_i}\]最naive的方式就是我们在体渲染方程中ray marching $N$个区间,然后每项都用$M$个区间估计transmittance,此时复杂度为$O(NM)$;不过,Transmittance Estimation的采样点可以复用体渲染方程的采样点,这样可以以$O(N)$的速度来估计整个方程。此时:
\[\sum_{i=1}^NT_r(p'_i\rightarrow p)\sigma_t(p'_i,w)L_s(p'_i,-w)\delta t_i\approx \sum_{i=1}^N\sigma_t(p'_i,w)L_s(p'_i,-w)\delta t_i\cdot e^{-\sum_{j=1}^i \sigma_t(p_j',w)\delta t_j}\]从当前采样点到下一个采样点,只需要 \(\text{Tr}_{i}=\text{Tr}_{i-1}\cdot e^{-\sigma_t(p_i',w)\delta t_{i-1}}\),不需要对每个点都要计算$M$次;同时使用固定步长非常常见,此时伪代码如下:
// N表示Ray marching区间长度, offset表示区间随便加一个偏移,不一定直接用交点。
float RayMarching(Volume volume, float3 pos, float3 dir,
float tMax, int N, float offset = 0.5f)
{
float stepSize = tMax / N;
float t = offset * stepSize;
pos += dir * offset * stepSize;
// 初始offset造成的transmittance,没有offset就是1。
float transmittance = exp(-volume.SampleExtinction(pos) * offset);
float radiance = 0; // 实时渲染直接RGB,后面sample出的也是RGB。
for (int i = 0; i < N; i++)
{
float newRadiance = GetRadiance(volume, pos, dir); // 我们假设计算出来的是sigma_t * L_s
radiance += newRadiance * stepSize * transmittance;
// 复用当前的采样点,更新下一段的transmittance
float extinction = volume.SampleExtinction(pos);
transmittance *= exp(-extinction * stepSize);
t += stepSize;
pos += dir * stepSize;
}
return radiance;
}
当然,也有一些更复杂的实现不使用固定步长,但是黎曼和的原理是不变的。
Pitfalls of Stochastic Estimators
在介绍离线渲染中对Transmittance的估计之前,我们需要首先厘清一个概念,解决一个常见误区。见到积分,我们可能很自然地会使用MC进行如下的估计:
\[\tau=\int_0^d\sigma_t(p+tw,w)\mathrm dt \Rightarrow \hat \tau=\frac{\sigma_t(X)}{p(X)}, E[\hat\tau]=\tau\]我们这里进行了简写,$\sigma_t(X)$表示$\sigma_t(p+xw,w), x\sim p(X)$。估计出了optical depth,直接$e^{-\hat\tau}$不就得到了对transmittance的估计,so easy!
Well, not that easy. 我们事实上做出了这样的假设:
\[f(E(X))=E(f(X))\]在我们这里即是$e^{-E(X)}=E(e^{-X})$。我们不妨先考虑离散随机变量,有$N$个可能的取值$x_1,\cdots ,x_N$,此时:
\[e^{-E(X)}=e^{-\sum_{i=1}^N p_i x_i}, E(e^{-X})=\sum_{i=1}^Np_ie^{-x_i}\]看着就不像相等吧!懂一点不等式的应该可以立刻看出来这是琴生不等式(Jensen’s Inequality):
\[\text{For } \sum_{i=1}^n a_i=1, f(x) \text{ is convex}\Rightarrow \forall x_1,\cdots, x_n, f(\sum_{i=1}^n a_ix_i)\leq \sum_{i=1}^n a_if(x_i), \text{equal iff. } x_i\equiv k\]显然$e^{-x}$是凸函数,所以这种方式估计出的结果是有偏的(Jensen’s gap),同时一定会高估。对于$X$为连续变量,可以通过概率的测度空间来同样地推导出来这样的结论。
另一方面,可能有人会说:既然$\sum_{i=1}^N e^{-\hat\tau_i}/N$不行,那我先把optical depth估的准一些,即令$\tau_0=\sum_{i=1}^N \hat\tau_i/N$,然后再计算$e^{-\tau_0}$,这样总是无偏的了吧!不幸的是,仍然不是,我们仅仅是把指数上的estimator换成了一个更准的estimator,然后进行一次采样作为估计结果,仍然可以通过琴生不等式得到$E[e^{-\bar X}]\geq e^{-E[\bar X]}$。例如,令$X_i\sim N(\mu,\sigma)$,则$E[e^{-\bar X}]=e^{-\mu+\frac{\sigma^2}{2N}}$,可以看到不是无偏的(unbiased),至多只能是一致的(consistent)。
总而言之,通过估计optical depth再直接指数计算一定会高估transmittance,不是无偏的estimator。
当然,如果做实时渲染,觉得bias就bias了,那也无所谓。
Delta-Tracking Estimator
分别观察PPP $P(N=0)$和Transmittance的式子:
\[P(N=0)=e^{-\int_{t_0}^{t_1}\lambda(t)\mathrm dt}\\ T_r(p\rightarrow p')=e^{-\int_0^d\sigma_t(p+tw,w)\mathrm dt}\]而extinction coefficient $\sigma_t$一定是非负数,因此transmittance就是rate function为$\sigma_t(t)$的PPP一次事件都不发生的概率。因此,只要我们按照Thinning的流程采出序列,只有序列为空代表$N=0$;进行足够多的Thinning采样,统计出$N=0$的频率作为概率即可估计。当然,由于我们采到第一个成功的点就代表失败,可以提前停下,于是就可以衍生出Delta Tracking的算法:

不同paper的记号不同,这里$\mu$代表$\sigma_t$,$\bar \mu$代表Thinning的上界。我们后面的$\mu$和$\sigma_t$也是混用的。
其中$t\geq d$就代表PPP离开了当前时间段,则一次都没有采到;而$\xi > \mu/\bar\mu$就代表了拒绝采样的过程。针对Delta-Tracking Estimation也可以进行更细粒度的上界划分(piecewise-constant / piecewise-linear / piecewise-polynomial,当然采样方式也要跟着变换),防止上界过大造成采出更多的采样点而需要更多的拒绝计算。
Ratio-Tracking Estimator
虽然Thinning很好地解决了bias的问题,但是这种模拟式的采样看起来不太高效;有没有可能利用整个采出来的序列来估计呢?我们首先观察Delta-Tracking的算法,事实上非常像光追的RR过程。猛一看可能不太像,我们不妨改写成递归形式:

第2行就像是在找交点,第3行像是达到了光源,第4-5行就是在RR,以一定的概率进行下一跳(第6行),或者直接停下。也就是说,Delta-Tracking的算法等价于下面的estimator转换:
\[\hat T_r(a,b)=\begin{cases} 0,& u\in [0,\mu(x)/\bar\mu)\\ \hat T_r(x,b),& \text{otherwise} \end{cases}\]从而$E[\hat T_r(a,b)]=E[(1-\mu(x)/\bar\mu)\cdot \hat T_r(x,b)]$,当然要求$x$的采样方式为指数采样。于是,欲估计$(a,b)$,首先采出$x_1$,然后估计$(x_1,b)$;欲估计$(x_1,b)$,于是采出$x_2$,…,依此类推(这和多跳光追的递归代码写成循环是一样的)。于是可以得到Ratio-Tracking Estimator:

第7行就是不断将结果转移到新的Estimator上,直到打出volume(此时transmittance为1)。
Residual Ratio-Tracking Estimator
可以注意到,我们在PPP中要进行补足,而补出来的$\lambda$越大,指数分布所需要的采样次数越多,一次估计的复杂度越高。当然前面说过可以通过更紧的上界来解决一部分问题,但如果$\lambda(t)$是比较一致的大,那本身的下界就很大了,上界再紧也没用。此时,我们可以统一地削除一部分下界来解决:
\[e^{-\int_0^d\sigma_t(p+tw,w)\mathrm dt}=e^{-\sigma_cd}\cdot e^{-\int_0^d(\sigma_t(p+tw,w)-\sigma_c)\mathrm dt}\]我们可以把$\sigma_t-\sigma_c$作为新的extinction来估计,于是就得到Residual Ratio-Tracking Estimator的算法:

其中$\bar\mu_r$为新的上界$\bar\mu-\mu_c$。
特别地,这个“削除”的过程也就是MC中降低方差的一种经典方法——control variate。简单来说,我们估计$X$可能估的不太好,但是减去另一个随机变量$Y-E[Y]$后却会变得好估计,这样期望不变但是可以降低方差。在体渲染中见到的都是减去一个统一的常数,因此就不再赘述control variate的相关理论了。
此外,原论文将这种削除进行了直观的解释,由此说明可以不使得$\sigma_c\leq \sigma_t$;但是这里我们为了让它还满足PPP,必须使得rate function处处不小于0。对原论文方法的严格证明可以通过后续的Estimator理论来完成。
Power-Series Estimator: Include All Above!
可以注意到,虽然对$X$的估计不能一般地用于对$f(X)$的估计,但是多项式的$f$本身却比较特殊。当然,$x^2$之类的函数进行一次估计还是有Jensen gap,但是独立的随机变量有一个非常特殊的性质:
\[E\left(\prod X_i\right)=\prod E(X_i), \text{if } X_i\text{ are independent}\]因此,假设要估计$a^2$,而我们只能找到$E[X]=a$,则可以采样两次相乘,从而$E[X_1X_2]=E[X_1]E[X_2]=a^2$。但是我们要估计的是$e^x$,应该如何转化为多项式呢?
没错,该无穷幂级数登场了!我们知道(从泰勒展开也易得):
\[e^x=\sum_{k=0}^\infty x^k/k!\]我们只要把每一项都估计出来再累加,由于期望的可加性就可以得到对$e^x$的估计,即:
\[e^x=\sum_{k=0}^\infty \frac{1}{k!} E[X]^k=\sum_{k=0}^\infty \frac{1}{k!} E\left[\prod_{i=1}^k X_i\right ],\text{where }E[X_i]=x,X_i\text{ are independent}\]然而,显然无穷的东西不能每项都算,所以使用不同的方法可以得到不同的Estimator。
Single-term Estimator
鲁迅曾说:我大抵得了什么病,看到无穷的空间,就会想到MC。
我们仍然可以对级数使用MC;可以注意到,对一般的函数$f(k)$:
\[\sum_{k=0}^\infty f(k)=\sum_{k=0}^\infty p(k)\frac{f(k)}{p(k)}=E_\kappa[f(\kappa)/p(\kappa)]\]其中$\kappa$为满足$p(\kappa)$的离散随机变量,且各个值的概率都不为0;我们每次只要抽一个index出来,估计这一项就可以了,也即:
\[\hat{e^x}=\frac{1}{k!p(k)}\prod_{i=1}^k X_i, \text{where }k\sim p(\kappa), E[X_i]=x,X_i\text{ are independent}\]在Transmittance estimation中,由于$x$为积分,因此可以继续MC。例如我们要估计$-\tau=-\int_0^d\sigma_t(p+tw,w)\mathrm dt$,则可以:
\[X_i=-\sigma_t(X)/p(X), X\sim p(x)\]由于负数部分级数正负号一直在变,数值上会有颠簸,因此我们也可以反过来估计 \(\tau_n\):
\[=\bar \tau-\tau=\int_o^d \sigma_{maj}-\sigma_t(p+tw,w)\mathrm dt=\int_o^d \bar \sigma_n(p+tw,w)\mathrm dt\]此时就是:
\[X_i=\sigma_n(X)/p(X),X\sim p(x)\]于是:
\[\hat T(a,b)=\frac{e^{-\bar\tau}}{k!p(k)}\prod_{i=1}^k \frac{\sigma_n(X_i)}{p(X_i)}, \text{where }k\sim p_1(\kappa), X_i\sim p_2(x)\]特别地,我们可以证明,之前的几种stochastic estimator全部都是single-term estimator:
-
Ratio-Tracking Estimator:可以注意到算法中对$t$的采样是指数采样,也即估计次数满足泊松分布$k\sim\text{Po}(\bar\tau)$,采样满足$\text{Exp}(\sigma_{maj})$,即:
\[p_1(k)=\bar\tau^k e^{-\bar\tau}/k!, p_2(x)=\sigma_{maj}/\bar\tau\]代入可得:
\[\frac{e^{-\bar\tau}}{k!\tau^k e^{-\bar\tau}/k!}\cdot\prod_{i=1}^k \frac{\sigma_n(X_i)}{\sigma_{maj}/\bar\tau}=\prod_{i=1}^k\frac{\sigma_n(X_i)}{\sigma_{maj}},\text{where }X_i\sim p_2(x)\]可以看到,和Ratio-Tracking Estimator的估计方式一致。
-
Delta-Tracking Estimator:可以认为仍然进行了$k$次事件,但是在算法中会在第$i$次事件提前终止估计(每次事件进行$\sigma_n/\sigma_{maj}$为概率的伯努利分布决定是否终止)。总体上来看,相当于以$\tau_n$的概率使得$\hat T=1$,其他为$\hat T=0$。
-
Residual Ratio-Tracking Estimator:类似Ratio-Tracking Estimator,只是削掉了下界,即$k\sim\text{Po}(\bar\tau-\tau_c)$, $x\sim\text{Exp}\left((\sigma_{maj}-\sigma_c)/(\bar\tau-\tau_c)\right)$。
从这个角度可以看到,我们只需要保证$\bar\mu_r\geq 0$,使得$k$的采样成立,但是并不一定必须使得$\sigma_c\leq \sigma_t$,因为我们从级数看已经不再依赖于PPP中rate必须是非负数,负数只是会出现颠簸。
TVCG 2020的论文从这个角度还套用了其他的分布,例如几何分布等。
Truncated Estimator
可以看到,single-term estimator每次估计出$k$个$X$,但是最后只求了一个$E[X]^k$,属实是浪费。期望的可加性是不受独立性约束的,所以我们明明可以把之前幂次全都算出来。于是就诞生了如下的Truncated Power-series Estimator:
\[\hat{e^x}=\sum_{k=0}^n\frac{1}{k!P_k}\prod_{i=1}^k X_i, \text{where }n\sim p(N), P_k=\text{Pr}[N\geq k],E[X_i]=x,X_i\text{ are independent}\]也就是$P_k$需要用(1-前面概率的累加)。在实际的估计中,我们只要采出一个$n$,然后再采出来$X_i$算上面的项就可以了。
我们下面对上述估计式的正确性进行证明。我们首先证明下式成立:
\[\sum_{n=0}^{\infty} \sum_{k=0}^n \frac{h(n) f(k)}{g(k)}=\sum_{k=0}^{\infty} \sum_{n=k}^{\infty} \frac{h(n) f(k)}{g(k)}\]更进一步地,我们可以抽象成证明下面的等式成立:
\[\sum_{i=0}^n \sum_{j=0}^i a_{i j}=\sum_{j=0}^n \sum_{i=j}^n a_{i j},\text{where } n=\infty\]我们先让是有限的,数形结合地来理解一下:
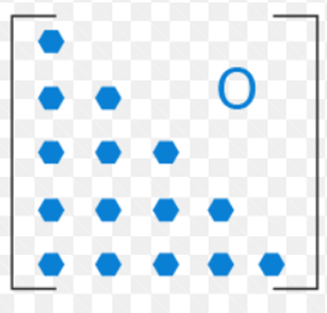
其中$a_{ij}$就是下三角矩阵的元素。LHS就是对每一行求和(外侧求和号为选定行),而RHS为对每一列求和(外侧求和号为选定列),最后求完和都是矩阵所有元素的和,因此两式相等。直观上看,$n\rightarrow\infty$就能证明我们的等式成立了。令$h(n)=p(n),g(k)=P_k$,于是得到:
\[\sum_{n=0}^{\infty} \sum_{k=0}^n \frac{p(n) f(k)}{P_k}=\sum_{k=0}^{\infty} \sum_{n=k}^{\infty} \frac{p(n) f(k)}{P_k}=\sum_{k=0}^{\infty} \frac{f(k)\sum_{n=k}^{\infty} p(n)}{P_k}\]又由于$P_k=\sum_{m=k}^{\infty}p(m)$,因此上下式约掉,得到:
\[\sum_{k=0}^{\infty} f(k)=\sum_{n=0}^{\infty} \sum_{k=0}^n \frac{p(n) f(k)}{P_k}=\sum_{n=0}^{\infty} p(n)\sum_{k=0}^n \frac{f(k)}{P_k}=E_n\left[\sum_{k=0}^n \frac{f(k)}{P_k}\right]\]吼吼,又有MC可以用吼。在我们的场景下,$f(k)=x^k/k!$,同时$x$还要被$X_i$估计,于是:
\[\hat{e^x}=\sum_{k=0}^n\frac{1}{k!P_k}\prod_{i=1}^k X_i, \text{where }n\sim p(N), P_k=\text{Pr}[N\geq k],E[X_i]=x,X_i\text{ are independent}\]证毕。
学过一点数学分析的其实可以发现,事实上无穷级数中的求和顺序是不可以随便交换的,我们上面的证明是不严格的。但是如果级数绝对收敛,则任意重排收敛到相同值,此时上述等式即成立(更一般的积分交换就是实变中的Fubini定理)。而在我们的场景下,级数绝对收敛到 \(e^{\lvert x\rvert}\),所以还是正确的。
Recursive Estimator
我们还可以把$e^x$写成递归的形式;首先:
\[e^x=\sum_{i=0}^\infty x^i/i!=1+\sum_{k=1}^\infty x^i/i!=1+\sum_{i=1}^\infty\prod_{j=1}^i x/j\]定义$a_{ij}=x/j$(从而每一列元素相同),我们还是数形结合一下:
我们上面的式子相当于每一行累乘,然后再累加。假设我们已经得到了右下角的三角形$M_{j+1}$,则向左扩展一列的三角形本质上是当前三角形乘以$x/j$,然后再加上左上角的元素,于是有:
\[M_j=(1+M_{j+1})x/j\]把$M_1$逐层展开,于是得到:
\[M_1=\frac{x}{1} \cdot(1+M_2)=\frac{x}{1}\left(1+\frac{x}{2} \cdot(1+M_3)\right) =\frac{x}{1}\left(1+\frac{x}{2} \cdot\left(1+\frac{x}{3}(1+M_4)\right)\right)=\cdots\]再加上我们最开始的1,代入$x=-\tau$,于是:
\[T(a, b)=1-\frac{\tau}{1}\left[1-\frac{\tau}{2}\left[1-\frac{\tau}{3}[\cdots]\right]\right]\]于是我们可以使用下面的估计式:
\[\hat T_j=1-\frac{\hat \tau}{j}\hat T_{j+1}\]和光追不断找下一跳很类似,所以可以RR。更一般地,我们同样可以插进一个$\bar\tau$,从而:
\[e^{-\bar\tau}\hat T_j=e^{-\bar\tau}+\frac{\hat \tau_n}{j}e^{-\bar\tau}\hat T_{j+1}\]把$e^{-\bar\tau}\hat T_j$合并一下作为新的$\hat T_j$,于是:
\[\hat T_j=e^{-\bar\tau}+\frac{\hat \tau_n}{j}\hat T_{j+1}\]这里只是按照原论文的公式插进来的,事实上用最上面的公式直接估出来$e^{\tau_n}$再直接乘以$e^{-\bar\tau}$也没问题。
RR得到:
\[\widehat{T}_j=e^{-\bar{\tau}}+ \begin{cases}\frac{\widehat{\tau}_n \widehat{T_{j+1}}}{j P_j} & u \in\left[0, P_j\right), \text { where } \mathrm{u} \in U[0,1] \\ 0 & \text { otherwise }\end{cases}\]再代入$\hat\tau_n=\sigma_n(X)/p(X)$,最终得到:
\[\widehat{T}_j=e^{-\bar{\tau}}+ \frac{\sigma_n(X)}{j p(X)P_j} \widehat{T_{j+1}}, \text{continued with probability }P_j\text{ for RR}\]Detailed Tricks
下面介绍的和Estimator本身的原理关系不是很大了,只是其中一些参数可以怎么选择,或者可以怎么优化方差,所以我们单独列出来一节。
At least 99%!
虽然stochastic estimator都是无偏的,但是在样本比较有限时仍然有明显噪声。因此,如果我们可以确定每一项的贡献,那么可以先把有绝大多数贡献的级数部分算上,在后面再进行采样来保证无偏。可以注意到:
\[e^x=\sum_{i=0}^\infty x^i/i!\]如果我们两侧同乘以$e^{-x}$,就有$1=\sum_{i=0}^\infty e^{-x}x^i/i!$。于是我们发现,本质上级数第$k$项的贡献和泊松分布$\text{Po}(x)$的$P(N=k)$是一致的。当然我们要算的$e^{\tau_n}$时不知道$\tau_n$的真值的,但是我们可以保证一个贡献的下界。例如,我们知道$\bar\tau\geq \tau_n$,因此如果我们使用$\text{Po}(\bar\tau)$来估计贡献,那么事件发生的次数会高估,CMF会增长的更缓慢,如下图:
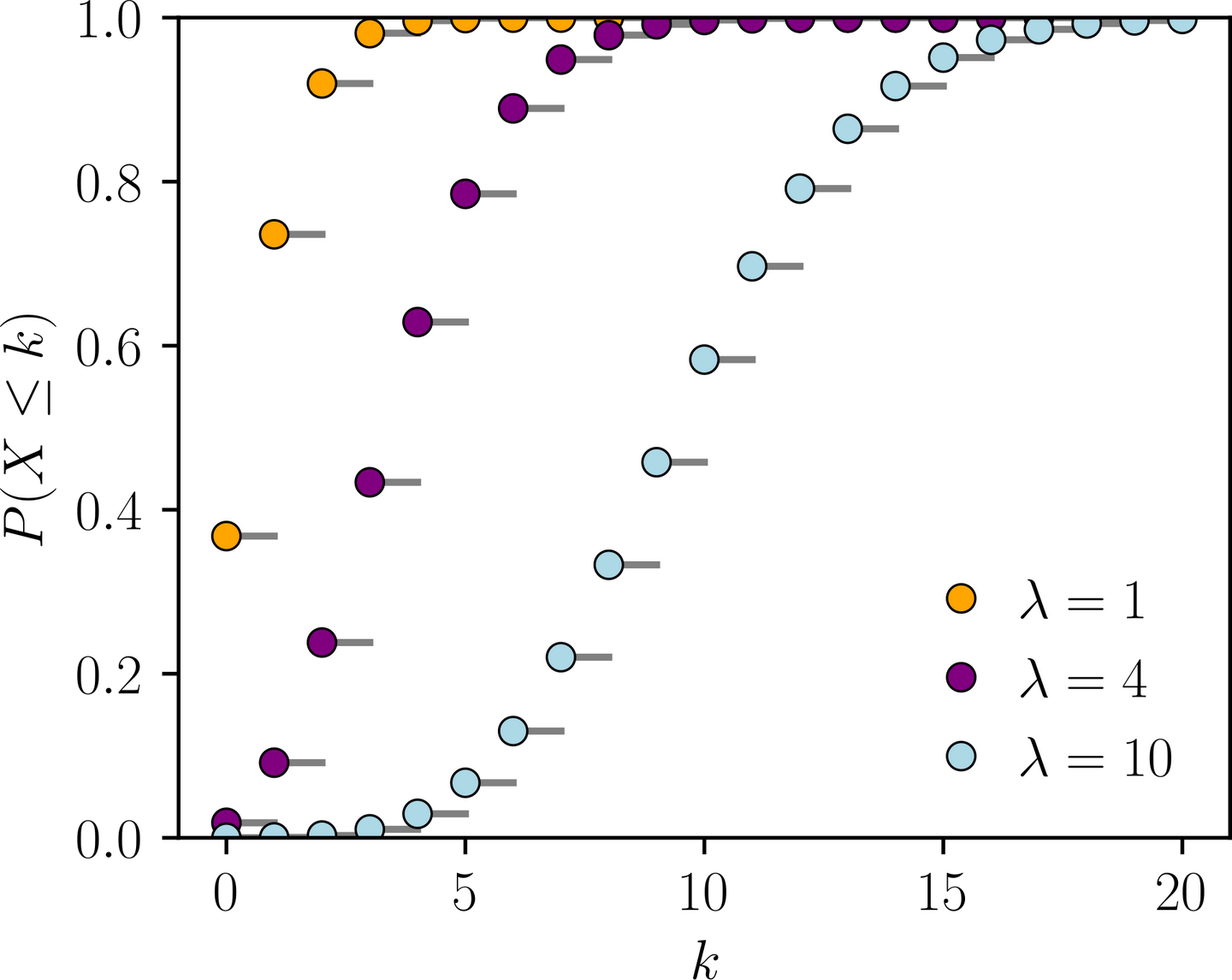
如果我们能保证在$\text{Po}(\bar\tau)$下一定到达的99%的贡献,则可以保证$\text{Po}(\tau_n)$一定达到了99%的贡献。
在Recursive Estimator中,我们于是可以利用下面的RR概率:
\[P_i=\left\{\begin{array}{cc} \bar{\tau} / i & \mathrm{CMF}_{\bar{\tau}}(i) \geq t \\ 1 & \text { otherwise } \end{array}\right., \text{where } t=0.99\]在Truncated Estimator中,也可以固定估计前$K$项(相当于前面的概率$P_k\equiv 1$),然后具体选择的项数$n$通过RR获得。
How to Choose Pivot?
可以注意到,$\sigma_c$的选择能够决定估计的效率。我们前面说明了$\sigma_c$可以选择下界削除来减小开销,后续使用级数的推导也进一步说明了可以不选择下界,任意值都可以。理想状态下,如果$\tau_c=\tau$,那我们就什么都不用估了,方差为0;但是$\tau$本身就不知道是多少。所以NVIDIA 2021提出可以多采一个样本$X_{n+1}$,通过$\hat\tau$作为轴点(不能使用$X_1,\cdots X_n$,会违反估计的独立性,造成有偏);轮流作为轴点估计$n+1$次,得到的结果再平均。
Maximize Utilization of Estimation
在Truncated Power-series Estimator中,虽然我们通过估计前$K$项提高了对样本的利用,但是可以注意到,第一项只使用了$X_1$,第二项只使用了$X_1\cdot X_2$,依次类推。我们完全可以利用上所有样本,第一项使用$\sum X_i/N$,第二项使用$\sum X_iX_j/C_{n}^2$,依次类推(这种方法在NVIDIA 2021中称为U-statistics)。
当然,求全组合显然复杂度太高,但是如果我们所有项都会用,这样可以使用下面的$O(N^2)$递推算法:

“Unbiased Ray Marching”
根据上面的算法,NVIDIA 2021提出了所谓的Unbiased ray marching estimator:

简单解释一下:
-
我们前面的$X_i=\sigma_n(X)/p(X)$只采了一次样作为MC估计,但是可以采多次取平均得到$X_i$;这里$M$就是确定要采样几次。
DetermineTupleSize是一个经验公式:- 首先根据Truncated Series CMF>0.99得到总共需要估计多少项(当然原文给出了grid search出的近似公式$N_{CMF}=$ $\lceil\sqrt[3]{(0.015+\bar{\tau})(0.65+\bar{\tau})(60.3+\bar{\tau})}\rceil$),认为至少才这些样本才能有比较好的结果;
- 然后再模拟Roulette来计算阶数$N$的期望$E[N]$。
- 最后$N_{CMF}/E[N]$作为每阶应该有多少样本数量进行平均。
-
\[e^x=\sum_{k=0}^K \frac{x^k}{k!}+\frac{c}{K+1}\left(\frac{x^{K+1}}{c K!}+\frac{c}{K+2}\left(\frac{x^{K+2}}{c^2 K!}+\ldots\right.\right.\]AggregateBKRoulette就是我们前面对阶数Roulette的过程,但是公式稍微泛化了一下:本质上没什么变化,原文虽然扯了一大通理论,最后直接in practice一个$K=c=2$,感觉没什么跟着扯的必要(。特别地,这里为了降低开销,会以$p_Z$的概率直接一项都不算。
-
中间求$X_i$看起来是ray marching,实际上只是采样点使用了等间距的,第一个点的采样是随机的(可以想象把积分分段,然后都MC;由于期望作和不需要独立性,所以分段的MC可以采同一个$u$);当然这种采样看起来就不太好,所以要配合其他方法来降噪声。
-
两行optional是在降低这种equiv-distance采样造成的误差;文章提了一下CP-rotation,指出这种采样相当于将函数做cyclic shift,那么两个端点在中间就会不连续,会提高误差。文章提出可以进行density reshuffling,公式就是:
\[\mu^{\star}(s):=\mu(s)+\left(\frac{1}{2}-\frac{s}{\ell}\right)(\mu(\ell)-\mu(0)) .\]就是进行了一下仿射变换,使得两个端点在这个变换下是相等的,同时保持$\mu^\star$的积分值和$\mu$一致。
-
最后
ElementaryMeans就是在求我们所有排列组合的平均,循环中以$X_i$作为轴点,最后通过Truncated Estimator计算出Transmittance的估计。
当然本文还给出了算得快但是bias的算法,就是我们前面说的$e^{E[X]}$,但是可以借用上面一些方法降低误差:

Appendix
Additional Results

P-series CMF就是Recursive Estimator + CMF at least 99%,最后两列是用了上述所有trick的NVIDIA 2021。
Skip Transmittance Estimation
我们前面说离线渲染有绕过Transmittance Estimation的方式;还是看下面的式子:
\[\hat L= \begin{cases} \frac{1}{q}T_r(p_s\rightarrow p)L_o(p_s,-w) & u\in[0,q)\\ \frac{1}{1-q}\int_0^{t_s} T_r(p'\rightarrow p)\sigma_t(p',w)L_s(p',-w)\mathrm dt & u\in[q,1] \end{cases}\]我们假设体是均匀的,$\sigma_t$为定值,此时$T_r=e^{-\sigma_t d}$。那么令$q=e^{-\sigma_td}$就可以在第一项把$T_r$约掉;对于第二项,注意到$1-e^{-\sigma_t d}$就是$\text{Exp}(\sigma_t)$的$\text{Pr}(t\in [0,d])$,则可以直接抽样$t\sim \text{Exp}(\sigma_t)$,当$t\in [d,+\infty)$时选择第一项即可。
又注意到第二个部分的积分正好需要一个$[0,d]$的MC,那么我们如果使用前面抽出来的$t$,等价于此时MC对应的PDF就是归一化的$\text{Exp}(\sigma_t)$即$\sigma_t e^{-\sigma_tt}/(1-T_s)=\sigma_t T_r(p+wt,p)/(1-T_s)$,从而第二项可以写为:
\[\begin{gathered} \sigma_t \int_0^{t_s} T_r\left(p^{\prime}\rightarrow p\right) L_s\left(p^{\prime},-w\right) /(1-q), q=T_s \\ \Rightarrow E s t=\frac{\sigma_t T_r\left(p_{\text {sample }} \rightarrow p\right) L_s\left(p_{\text {sample }},-w\right)}{\sigma_t T_r\left(p_{\text {sample }} \rightarrow p\right) /\left(1-T_s\right)} /\left(1-T_s\right) \end{gathered}\]约掉,于是得到:
\[\hat L= \begin{cases} L_o(p_s,-w) & t\in[d,\infty)\\ L_s(p+wt,-w) & t\in[0,d] \end{cases},\text{where } t\sim \text{Exp}(\sigma_t)\]当然,我们这里假设了体均匀;如果$\sigma_t$变化,则可以利用类似Thinning的原理先补足到均匀,再把多的部分$\sigma_n$“去掉”:
\[\begin{gathered} L_i(p, w)=\boldsymbol{T}_{\boldsymbol{m a j}}\left(\boldsymbol{p}_{\boldsymbol{s}} \rightarrow \boldsymbol{p}\right) L_o\left(p_s,-w\right)+\boldsymbol{\sigma}_{\boldsymbol{m} a j} \int_0^{t_s} \boldsymbol{T}_{\boldsymbol{m} a j}\left(\boldsymbol{p}^{\prime} \rightarrow \boldsymbol{p}\right) \boldsymbol{L}_{\boldsymbol{n}}\left(p^{\prime},-w\right) \mathrm{d} t \\ L_n(p, w)=\left(\sigma_a(p, w) L_e(p, w)+\sigma_s(p, w) \int_{S^2} \phi\left(p, w_i, w\right) L_i\left(p, w_i\right) \mathrm{d} w_i+\boldsymbol{\sigma}_{\boldsymbol{n}} \boldsymbol{L}_{\boldsymbol{i}}(\boldsymbol{p}, \boldsymbol{w})\right) / \boldsymbol{\sigma}_{\boldsymbol{m a j}} \\ T_{m a j}\left(p^{\prime} \rightarrow p\right)=e^{-\sigma_{m a j} d} \end{gathered}\]当然严格证明这里求出的radiance和原radiance等价还是要用到常微分方程,这里就略过了。但是这样就可以沿用我们上面的估计方法,只是要多的$\sigma_n$也算作一种可能的光路:
\[\hat L(p,w)= \begin{cases} L_o(p_s,-w) & t\in[d,\infty)\\ L_n(p+wt,-w) & t\in[0,d] \end{cases},\text{where } t\sim \text{Exp}(\sigma_{maj})\\\]然后$L_n$的三项RR一下:
\[\hat L_n(p,w)= \begin{cases} L_e(p,w) & u\in[0,\sigma_a)\\ \int_{S^2} \phi\left(p, w_i, w\right) L_i\left(p, w_i\right) \mathrm{d} w_i & u\in[\sigma_a, \sigma_t)\\ \hat L(p,w),& u\in[\sigma_t,\sigma_{maj}) \end{cases},\text{where } u\in U[0,\sigma_{maj}]\\\]这样我们就规避掉了所以Transmittance Estimation。上面式子的物理直觉就是:一束光可能遇到三种事件:
- 自发光粒子会补radiance;
- 散射事件,光散射到其他方向(我们MC第二项采出的新光路);
- 空粒子事件,就是我们补足$\sigma_{maj}$凭空假想的粒子,实际上这次事件没有发生,光路继续沿当前方向传播。
Mathematical Formulation of PPP
我看很多资料对PPP的形式化定义是这样的:
\[\forall t \geq 0, \lim _{s \rightarrow 0^{+}} P\left(N_{t+s}-N_t=1\right) / s=\lambda(t), \lim _{s \rightarrow 0^{+}} P\left(N_{t+s}-N_t \geq 2\right) / s=0\]我不太懂怎么能证明出任意一段$N\sim \text{Po}(\int_{t_0}^{t_1}\lambda(t)\mathrm dt)$,只先证出了$P(N=0)$:
\[P(N=0)=\lim_{n\rightarrow\infty}\prod_{i=0}^{n-1}(1-\lambda(t+i \delta t) \delta t), \text { where } n \delta t=T\]从极限的定义出发,我们可以定义相应的数列,于是两侧取log:
\[\log P_n(N=0)=\sum_{i=0}^n \log (1-\lambda(t+i \delta t) \delta t)\]注意到:
\[\forall \epsilon>0, \exists N, \text{s.t. } \forall n>N, 0 \leq_n-\lambda(t) \delta t-\log (1-\lambda(t) \delta t) \leq \epsilon \delta t\]故:
\[-\epsilon T+\sum_{i=0}^n-\lambda(t+i \delta t) \delta t \leq \sum_{i=0}^n \log (1-\lambda(t+i \delta t) \delta t) \leq \sum_{i=0}^n-\lambda(t+i \delta t) \delta t\]两侧取指数,然后由夹逼定理得到$P(N=0)=e^{-\int_t^{t+T} \lambda(t) \mathrm{d} t}$。证毕。
直觉告诉我还是可以数学归纳法,但是由于和体渲染没关系,后面就懒得想了(
其他参考文献
关于体渲染的基础理论可以看看PBRT。
与体渲染无关,而我实际上看了的,列在下面:
- Particle Filters for Partially Observed Diffusions, Fearnhead et.al.
- An Introduction to the Theory of Point Processes: Volume I: Elementary Theory and Methods, 2nd ed., D.J. Daley & D. Vere-Jones.
-
Generating Nonhomogeneous Poisson Processes, Pasupathy.
- Simulation of nonhomogeneous poisson processes by thinning, Lewis & Shedler.